
Kubernetes入门学习

Kubernetes入门学习
weh12Kubernetes简介
Kubernetes是一个开源的容器编排平台

用于自动化部署、扩展和管理容器化应用程序。以下是Kubernetes的一些关键特性和概念:
容器编排:Kubernetes帮助用户管理容器的生命周期,包括部署、运行、扩展、监控和更新。
服务发现和负载均衡:Kubernetes可以为容器提供内部和外部的负载均衡,并且能够自动发现服务。
存储编排:Kubernetes允许用户自动挂载存储系统,无论是本地磁盘、公共云提供商的存储还是网络存储系统。
自动部署和回滚:Kubernetes支持声明式的更新,可以自动回滚到之前的版本,如果新版本出现问题。
自动完成声明式部署:用户可以声明系统应有的状态,Kubernetes会自动将当前状态变更为期望状态。
自动重启:如果容器崩溃,Kubernetes会自动重启该容器。
自动放置:Kubernetes可以自动决定在哪个节点上运行容器,以优化资源利用。
密钥和配置管理:Kubernetes可以存储和管理敏感信息,如密码和密钥,并将其传递给容器,而无需在堆栈配置中暴露。
扩展性:Kubernetes的API使得开发者可以轻松开发自定义的扩展插件。
集群联邦:多个Kubernetes集群可以组成一个逻辑上的大集群,以便跨多个云或数据中心共享资源。
Kubernetes的核心组件包括:
- Kubernetes Master:负责调度Pods、处理集群事件等。
- Node:运行Pods的机器。
- Pod:Kubernetes中的基本部署单元,可以包含一个或多个容器。
- Service:定义了一种访问Pod的方式,它是一个稳定的接口,可以访问到Pods。
- Deployment:用于描述应用的期望状态,包括应用的副本数等。
- Ingress:管理外部访问应用的规则。
- **Persistent Volume (PV) 和 Persistent Volume Claim (PVC)**:用于存储的抽象,允许Pods使用持久化存储。
- Namespace:用于在同一个物理集群中隔离不同的用户或项目。
Kubernetes的设计目标是提供一个平台,它能够运行分布式系统,并具有高可用性、可扩展性和灵活性。它已经成为容器编排领域的事实标准,被广泛应用于生产环境中。
Kubernetes组件
Node基本信息
首先从一个最简单的节点开始, 一个节点就是一个物理机或者虚拟机, 在这个节点上我们可以运行一个或多个pod, Pod是kubernetes的最小调度单元, 一个pod就是一个或多个应用容器的组合, 它创建了一个容器的运行环境, 在这个环境中, 容器可以共享一些资源, 比如网络 存储以及一些运行时的配置等
假设我们的系统包括一个应用程序和一个数据库, 就可以将应用程序和数据库分别放到两个不同的pod中, 一般情况下, 我们建议一个pod中只运行一个容器, 但不是说一个pod中只能运行一个容器, 因为这样是为了实现应用程序的解耦和扩展, 一个pod可以有多个容器, 但是一般也仅限于这些容器是高度耦合的情况, 它们之间为了实现某种功能或者共享某些资源, 而不得不放到同一个pod中
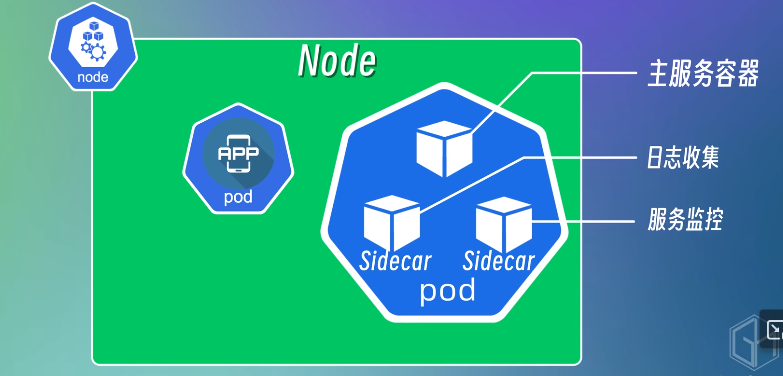
现在我们已经将应用程序和数据库, 分别放到了两个pod中, 应用程序要访问数据库的话, 就需要知道数据库IP地址, 这个IP地址是在Pod创建的时候自动分配的, 它是一个集群内部的IP地址
Pod之间可以通过这个IP地址来进行通信, 这样我们的应用程序就可以通过这个IP地址来访问数据库了, 但是这个有两个问题需要注意一下:
一个是这个IP地址是一个内部的IP地址, 在集群外部是无法访问的
二是pod并不是一个稳定的实体, 也就意味着它们非常容易被创建或者销毁, 在发生故障的时候, Kubernetes会自动销毁pod重新创建新的pod来代替它, 这个时候IP地址也会发生变化
为了解决问题二, Kubernetes提供了一个叫做Service的资源对象, 它可以将一组pod封装成一个服务, 这个服务可以通过一个统一的入口来访问, 拿刚才的例子来说, 我们可以将应用程序和数据库的pod分别封装成两个Service(服务), 这样应用程序就可以通过Service的IP地址来访问数据库, 当pod发生故障的时候, 即使它的IP地址发生了变化, 但Service的IP地址不会变, Service会自动的请求转发到其他健康的pod上, 以此来解决pod的IP不稳定的问题
内部和外部服务
Service也分内部服务和外部服务, 内部服务是一些我们不想暴露给外部的服务, 比如MySQL数据库 缓存 消息队列等等, 这些服务只需要在集群内部被访问就可以,
而相应的, 有些服务是要暴露给外部的, 比如一些微服务的后端API接口或者是一些给用户使用的前端界面等等
外部服务有几种常用的类型, 其中一种类型就是NodePort, 它会在节点上开放一个端口, 然后将这个端口映射到Service的IP地址和端口上, 这样就能通过节点的IP地址和端口来访问Service, 在开发或者测试阶段, 使用这种IP和端口号的方式是没有问题的, 但是在生产环境中, 通常都是通过域名来访问服务的, 这个时候就用到了另一个资源对象Ingress
Ingress是用来管理从集群外部访问集群内部服务的入口和方式的, 可以通过Ingress来配置不同转发规则, 从而根据不同的规则来访问集群内部不同的Service以及Service所对应的后端pod, 还可以通过Ingress来配置域名, 这样就可以将原本使用IP地址和端口号的方式, 转换成使用域名的方式来访问Service
另外Ingress也可以配置一些其他功能, 比如负载均衡 SSL证书等等
应用程序和数据库的耦合问题
举个例子, 比如我们的应用程序需要访问数据库, 通常的做法是把数据库的地址和端口等连接信息写到配置文件或者环境变量中, 然后在应用程序中读取这些配置信息, 但是这样的话配置信息就和应用程序耦合在一起了, 一旦数据库的地址或者端口发生了变化, 那么我们就需要重新编译应用程序, 然后再重新部署到集群中, 这样不但非常麻烦, 而且还会造成应用程序的停机时间, 这对于一些需要7x24小时不间断运行的系统或者服务来说, 显然是不能接受的,
为了解决这个问题, kubernetes提供了一个叫做ConfigMap的组件, 它可以将一些配置信息封装起来, 然后就可以在应用程序中读取和使用了
有了ConfigMap, 我们就可以把配置信息和应用程序的镜像内容分离开来, 这样就可以保持容器化应用程序的可以移植性, 当数据库的地址和端口发生变化的时候, 我们也只需要修改ConfigMap对象中的配置信息, 然后重新加载pod就行了, 不需要重新编译, 这样就实现了应用程序和数据库的解耦
有一点需要注意到, ConfigMap中的配置信息都是明文的, 如果配置信息中包含了一些敏感信息, 比如数据库的用户名或者密码等等, 那么就不建议存储在ConfigMap
为了解决这个小问题, Kubernetes提供了另一个叫做Secret的组件, 和ConfigMap类似, 它可以将一些敏感信息封装起来, 然后就可以在应用程序中使用和读取了, Secret只是做了Base64的编码并没有加密, 还要依靠Kubernetes的其他安全机制来保证系统安全
持久化存储
当容器被销毁或者重启的时候, 容器中的数据也会跟着消失, 这对于一些需要持久化存储的应用程序, 比如数据库来说显然是不行的
为了解决这个问题, Kubernetes提供了一个叫做Volume的组件, 它可以将一些持久化的资源挂载到集群中的本地磁盘上, 或者挂载到集群外部的远程存储上, 这样即使容器被销毁或者重启, 这些数据也不会丢失
应用程序的高可用性
举个例子, 比如如果应用程序所在的节点发生了故障, 或者需要对节点进行升级和更新维护的时候, 应用程序就会停止服务, 这样就有可能造成一些不必要的麻烦和损失
解决方案其实也非常简单, 既然只有一个节点不行的话, 那么就多加几个节点, 简单来说就是把所有东西都复制一份, 然后放到另外一个节点上
Kubernetes提供了一个叫做Deployment的组件, 它可以定义和管理应用程序的副本数量以及应用程序的更新策略, 可以简化应用程序的部署和更新操作
在之前我们提到过, pod可以理解为在容器的上面加了一层抽象, 这样就可以将一个或多个容器组合在一起, 而Deployment就可以理解为在pod上再加上一层抽象, 这样就可以将一个或者多个pod组合在一起, 并且还具有副本控制 滚动更新 自动扩缩容等高级特性和功能
副本控制是指可以定义和管理应用程序的副本数量, 比如我们可以定义一个应用程序的副本数量为3个, 那么如果有副本发生故障的时候, 会自动创建一个新的副本来替代它
对于管理数据库的持久化, kubernetes提供了另一个组件叫StatefulSet来保证数据库的高可用性, 用法根Deployment相似
StatefulSet适用于需要持久化存储、网络标识和有序操作的场景,例如数据库(如 MySQL、PostgreSQL)、消息队列(如 RabbitMQ、Kafka)和分布式存储系统等。
创建StatefulSet的基本 YAML 文件示例如下:
1 | apiVersion: apps/v1 |
在这个例子中,我们定义了一个名为 web的 StatefulSet,它管理了三个 nginx 的Pod,每个 Pod 都有一个名为 www 的持久卷
Kubernetes架构
Kubernetes是一个典型的Master-Worker架构, Master-Node负责管理整个集群, Worker-Node负责运行应用程序和服务

每个工作节点上的容器都有一个容器运行时container-runtime, 在学习Docker的时候, 我们知道也有一个运行时Docker-Engine, 在Kubernetes中可以选择任何你想要的运行时

kubelet是 Kubernetes 集群中每个节点上运行的主要“节点代理”,它负责处理 Master 节点下发到本节点的任务,管理 Pod 和其中的容器。
Kube-proxy是 Kubernetes 集群中的一个重要组件,主要负责实现服务的网络代理和负载均衡功能。
Master-Worker核心组件
kube-apiserver是 Kubernetes 集群中的核心组件之一,主要负责处理所有与 Kubernetes API 的交互。以下是它的一些关键特性和功能:
API 处理:
kube-apiserver提供 Kubernetes 各类资源对象(如 Pod、Deployment、Service 等)的增、删、改、查及 Watch 等 HTTP REST 接口[^1^]。它接收并响应来自客户端(如kubectl、应用程序、其他组件等)的 RESTful API 请求。数据存储:
kube-apiserver与etcd交互,持久化保存集群的状态和配置。它是整个 Kubernetes 系统的数据总线和数据中心。认证与授权:
kube-apiserver进行身份验证和访问控制,确保只有授权的用户和系统组件能够对 Kubernetes 资源进行操作。它提供了认证、授权、准入控制、资源配额等集群安全机制。架构:
kube-apiserver的架构可以分为四层和一个监听机制,包括 API 层、认证授权层、准入控制层和 etcd 交互层。端口:在默认情况下,
kube-apiserver进程在本机的 8080 端口(对应参数--insecure-port)提供 REST 服务,并且可以同时启动 HTTPS 安全端口(--secure-port=6443)来加强 REST API 访问的安全性。工作原理:
kube-apiserver提供了 Kubernetes 的 REST API,实现了认证、授权和准入控制等安全功能,同时也负责了集群状态的存储操作。访问方式:可以通过
kubectl命令行工具、客户端库和第三方工具与 Kubernetes 集群进行交互。
kube-apiserver 作为 Kubernetes 集群的中枢,所有对集群状态的操作都通过它来进行,因此它的地位非常重要。
Scheduler是一个关键组件,负责将Pods(容器的逻辑封装)调度到集群中的节点上。它需要考虑资源需求、硬件/软件/策略约束、亲和性和反亲和性规则、数据位置、工作负载间干扰和最终用户指定的调度要求。Controller Manager是一个核心组件,主要负责管理集群中的各种Pod,以确保集群的实际状态与用户的期望状态保持一致。etcd是一个开源的分布式键值存储系统,主要用于共享配置和服务发现。
以下是etcd的一些核心组件和它们的作用:
Client层:包含client v2和v3两个大版本的API客户端,用于客户端与etcd服务器之间的通信。
API网络层:主要包含客户端访问服务器和服务器节点之间的通信协议。客户端访问服务器分为两个版本:v2
API采用HTTP/1.x协议,v3
API采用gRPC协议;服务器之间的通信是指节点间通过Raft算法实现数据复制和Leader选举等功能时使用的HTTP协议。Raft算法层:实现了Leader选举、日志复制、ReadIndex等核心算法特性,用于保障etcd多节点间的数据一致性、提升服务可用性等,是etcd的基石和亮点。
功能逻辑层:etcd核心特性实现层,如典型的KVServer模块、MVCC模块、Auth鉴权模块、Lease租约模块、Compactor压缩模块等。其中MVCC模块主要有treeIndex模块和boltdb模块组成。
存储层:包含预写日志WAL模块、快照Snapshot模块、boltdb模块。WAL可保障etcd crash后数据不丢失,boltdb则保存了集群元数据和用户写入的数据。
etcd的特点包括简单性、键值对存储、监测变更、安全性、快速性和可靠性。
minikube搭建环境

除了搭建一个kubernetes集群环境之外, 你还需要使用kubectl这个命令行工具来同你创建的kubernetes集群进行交互, 比如创建一个Pod或者Service查看集群的状态等等
基本安装流程
以下是在你的电脑上使用 Minikube 搭建开发环境的步骤:
安装 prerequisites
- Docker: Minikube 需要 Docker 来运行虚拟机或者容器。
- kubectl:
- VirtualBox 或 VMware (如果需要虚拟机支持):
安装 Minikube
打开终端。
运行以下命令安装 Minikube:
1 | sudo curl -LO |
启动 Minikube
切换到具有相应权限的目录。
运行以下命令启动 Minikube:
1 | # 国内用户第一次下载可能会遇到依赖下载失败的情况, 可以切换国内镜像源下载 |
- 你可以在新的终端窗口中运行
kubectl cluster-info检查集群是否启动成功。
部署应用程序
使用
kubectl apply -f <your-deployment.yaml>命令部署你的应用(假设你有
一个已定义的 Kubernetes Deployment YAML 文件)。确认部署是否成功,可以使用以下命令:
1 | kubectl get pods |
- 你可以通过访问 Minikube 指定的 IP 地址来测试应用程序。
停止 Minikube
当你完成开发工作后,你可以停止 Minikube:
1 | minikube stop |
删除 Minikube
如果你想要从系统中完全删除 Minikube,可以运行以下命令:
1 | minikube delete |
以上就是使用 Minikube 在本地计算机上搭建 Kubernetes 开发环境的步骤。
Minikube 为开发者提供了一个完整的 Kubernetes 环境,可以在不离开本地环境的情
况下测试和开发应用程序。
ubuntu上搭建minikube
在 Ubuntu 22 上安装 Minikube
安装依赖
首先,确保你的系统安装了必要的依赖项:
1 | sudo apt-get update |
安装 Docker
Minikube 可以使用 Docker 作为其虚拟化驱动程序。按照以下步骤安装 Docker:
1 | sudo apt-get install -y docker.io |
验证 Docker 是否安装成功:
1 | docker --version |
示例输出:
1 | Docker version 20.10.7, build f0df350 |
使用国内镜像安装 kubectl
由于网络原因无法访问 Google 的 Kubernetes 存储库,我们可以使用 Azure China 的 Kubernetes 镜像源来下载和安装 kubectl:
1 | 1.获取稳定版本号: |
安装 Minikube
从 Minikube 的官方网站下载并安装最新版本的 Minikube:
1 | curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 |
验证 Minikube 是否安装成功:
1 | minikube version |
示例输出:
1 | minikube version: v1.33.1 |
启动 Minikube
使用以下命令启动 Minikube:
1 | minikube start --driver=docker |
示例输出:
1 | 😄 minikube v1.33.1 on Ubuntu 22.04 (vbox/amd64) |
启用 Ingress 插件
为了使局域网内的其他机器能够访问 Minikube Dashboard,你需要启用 Ingress 插件:
1 | minikube addons enable ingress |
示例输出:
1 | 💡 ingress is an addon maintained by Kubernetes. For any concerns contact minikube on GitHub. |
让局域网内其他机器访问 Minikube Dashboard
使用
kubectl port-forward:
- 1.获取 Dashboard 服务名称:
1 | kubectl get svc -n kubernetes-dashboard |
示例输出:
1 | NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE |
- 2.进行端口转发:
1 | kubectl port-forward -n kubernetes-dashboard service/kubernetes-dashboard 8080:80 --address 0.0.0.0 & |
- 3.在局域网内的其他机器上,通过以下 URL 访问 Dashboard:
1 | http://<your-host-ip>:8080/ |
其中 <your-host-ip> 是运行 Minikube 的主机的 IP 地址。
如果需要后台运行,可以用nohup命令:
1 | nohup kubectl port-forward -n kubernetes-dashboard service/kubernetes-dashboard 8080:80 --address 0.0.0.0 > port-forward.log 2>&1 & |
设置防火墙(可选)
如果你在机器上启用了防火墙,可能需要开放相应的端口:
1 | sudo ufw allow 8001 |
使用K3s和Multipass搭建环境
Multipass是什么?
Multipass 是一个开源的虚拟化工具,它允许用户在一个安全的沙箱环境中运行他们的应用程序。这个沙箱环境是一个轻量级的虚拟机(VM),可以用于开发、测试和部署应用程序,而不必担心会影响宿主机器的系统环境。
Multipass 适用于需要隔离开发环境或测试应用程序的场合,尤其是对于那些希望在多种操作系统之间保持一致性开发流程的开发者来说,它是一个非常有用的工具。
安装和使用Multipass

使用 Multipass 创建虚拟机的具体语法相对简单,以下是一些常用的 Multipass 命令和参数:
SHELL
multipass launch [OPTIONS]
以下是 launch 命令的一些常见选项:
-n,--name NAME:指定虚拟机的名称。-i,--image IMAGENAME:指定要启动的镜像名称。如果你不提供这个选项,Multipass 将使用默认的官方镜像。-m,--memory MEMORY:指定分配给虚拟机的内存大小(以 MB 为单位)。-c,--cpus CPUS:指定虚拟机可以使用的 CPU 核心数。-d,--disk SIZE:指定初始磁盘大小(以 GB 为单位)。--vm-type TYPE:指定虚拟机的类型(例如,”normal”,”headless” 等)。--cloud-init CLOUDINIT:使用 cloud-init 脚本来自定义虚拟机设置。
以下是一个创建虚拟机的具体例子:
SHELL
multipass launch -n my-vm --image ubuntu latest --memory 2048 --cpus 2
这个命令将会创建一个名为 “my-vm” 的 Ubuntu 虚拟机,分配 2048MB 的内存和 2 个 CPU 核心。
如果你想导入一个特定的操作系统镜像并且设置磁盘大小和类型(例如 SSD),可以使用以下命令:
SHELL
multipass launch -n my-vm --image ubuntu latest --disk-size 30G --storage-engine lvm
这个例子中,我们将创建一个名为 “my-vm” 的虚拟机,使用 Ubuntu 镜像的最后一个版本,分配 30GB 的磁盘空间,并选择 LVM 作为存储引擎。
其他常用 Multipass 命令
multipass shell NAME:进入指定沙盒的终端。multipass info NAME:获取关于指定沙盒的信息。multipass mount [OPTIONS] FILE|DIR [MOUNTPOINT]:挂载文件或目录到沙盒中。multipass umount NAME MOUNTPOINT:从沙盒卸载已挂载的文件或目录。multipass delete NAME:删除指定的沙盒。multipass list:列出所有创建的沙盒。

multipass默认是不允许直接通过ssh进入的, 需要配置ssh

K3s安装和使用
K3s介绍
k3s 是一个轻量级的Kubernetes发行版,它是 Rancher Labs 推出的一个开源项目,
旨在简化Kubernetes的安装和维护,同时它还是CNCF认证的Kubernetes发行版。
本指南帮助你使用默认选项快速启动集群。安装部分更详细地介绍了如何设置 K3s。
有关 K3s 组件如何协同工作的信息,请参阅架构。
Kubernetes 新手?Kubernetes 官方文档介绍了一些很好的基础知识教程。
安装脚本
K3s 提供了一个安装脚本,可以方便地将其作为服务安装在基于 systemd 或 openrc 的系统上。该脚本可在 https://get.k3s.io 获得。要使用这种方法安装 K3s,只需运行:
1 | curl -sfL https://get.k3s.io | sh - |
备注: 中国用户,可以使用以下方法加速安装:
1 | curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh - |
运行此安装后:
- K3s 服务将被配置为在节点重启后或进程崩溃或被杀死时自动重启。
- 将安装其他实用程序,包括
kubectl、crictl、ctr、k3s-killall.sh和k3s-uninstall.sh。 - kubeconfig 文件将写入到
/etc/rancher/k3s/k3s.yaml,由 K3s 安装的 kubectl 将自动使用该文件。
单节点 Server 安装是一个功能齐全的 Kubernetes 集群,它包括了托管工作负载 pod 所需的所有数据存储、control
plane、kubelet 和容器运行时组件。除非你希望向集群添加容量或冗余,否则没有必要添加额外的 Server 或 Agent 节点。
要安装其他 Agent 节点并将它们添加到集群,请使用 K3S_URL 和 K3S_TOKEN 环境变量运行安装脚本。以下示例演示了如何添加 Agent 节点:
1 | curl -sfL https://get.k3s.io | K3S_URL=https://myserver:6443 K3S_TOKEN=mynodetoken sh - |
备注: 中国用户,可以使用以下方法加速安装:
1 | curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn K3S_URL=https://myserver:6443 K3S_TOKEN=mynodetoken sh - |
K3S_URL 参数会导致安装程序将 K3s 配置为 Agent 而不是 Server。K3s Agent 将注册到在 URL 上监听的 K3s Server。K3S_TOKEN 使用的值存储在 Server 节点上的 /var/lib/rancher/k3s/server/node-token 中。
备注: 每台主机必须具有唯一的主机名。如果你的计算机没有唯一的主机名,请传递
K3S_NODE_NAME环境变量,并为每个节点提供一个有效且唯一的主机名。
创建和配置master节点
首先我们需要使用multipass创建一个名字叫做k3s的虚拟机,
1 | multipass launch --name k3s --cpus 2 --memory 8G --disk 10G |
虚拟机创建完成之后,
可以配置SSH密钥登录,
不过这一步并不是必须的,
即使不配置也可以通过multipass exec或者multipass shell命令来进入虚拟机,
然后我们需要在master节点上安装k3s,
使用k3s搭建kubernetes集群非常简单,
只需要执行一条命令就可以在当前节点上安装k3s,
打开刚刚创建的k3s虚拟机,
执行下面的命令就可以安装一个k3s的master节点,
1 | # 安装k3s的master节点 |
国内用户可以换成下面的命令,使用ranher的镜像源来安装:
1 | curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh - |
安装完成之后,可以通过kubectl命令来查看集群的状态,
1 | sudo kubectl get nodes |
创建和配置worker节点
接下来需要在这个master节点上获取一个token,
用来作为创建worker节点时的一个认证凭证,
它保存在/var/lib/rancher/k3s/server/node-token这个文件里面,
我们可以使用sudo cat命令来查看一下这个文件中的内容,
1 | sudo cat /var/lib/rancher/k3s/server/node-token |
将TOKEN保存到一个环境变量中
1 | TOKEN=$(multipass exec k3s sudo cat /var/lib/rancher/k3s/server/node-token) |
保存master节点的IP地址
1 | MASTER_IP=$(multipass info k3s | grep IPv4 | awk '{print $2}') |
确认:
1 | echo $MASTER_IP |
使用刚刚的TOKEN和MASTER_IP来创建两个worker节点
并把它们加入到集群中
1 | # 创建两个worker节点的虚拟机 |
这样就完成了一个多节点的kubernetes集群的搭建。








